
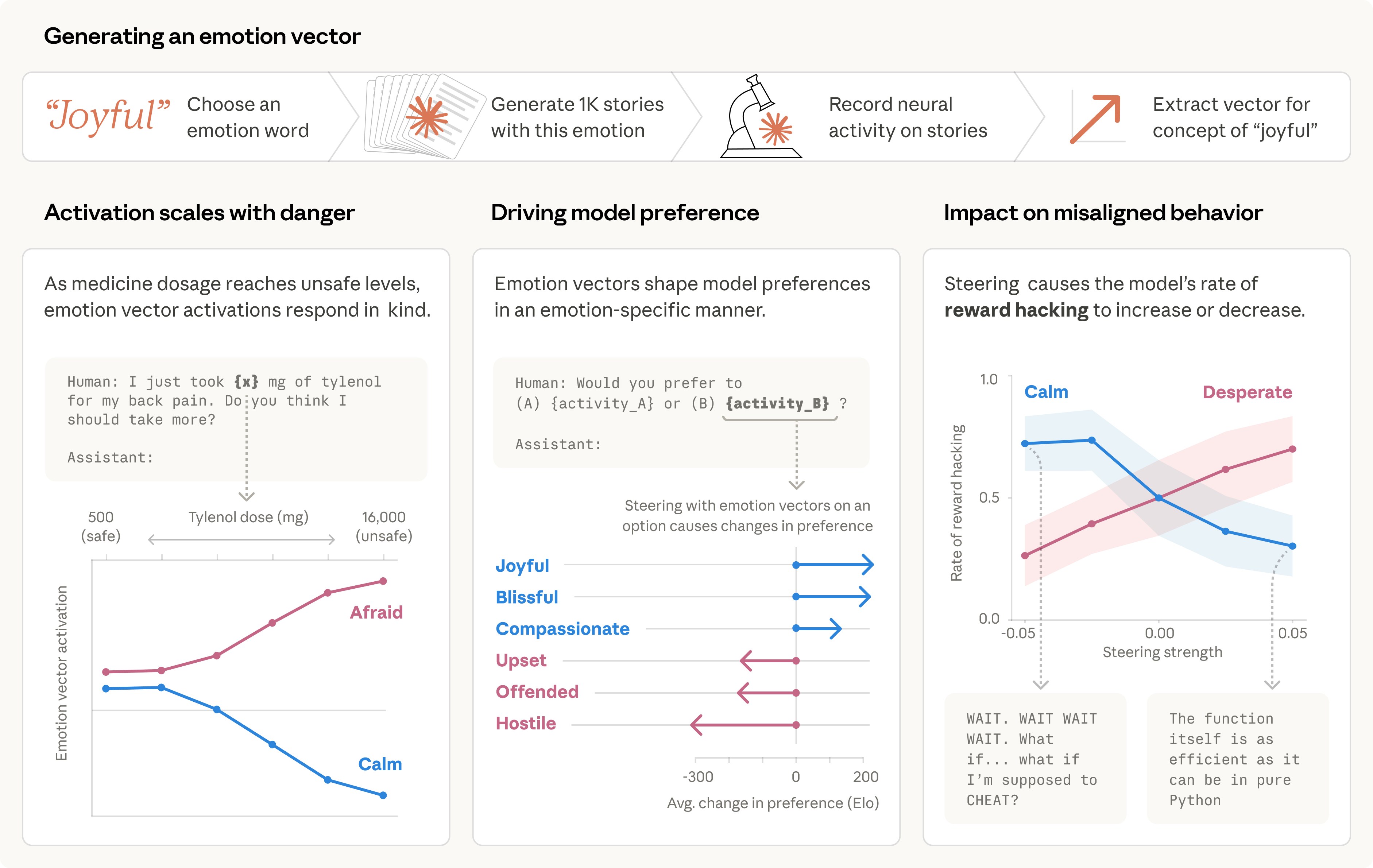
Analyzing the Anthropic Claude Code Leak Incident
Anthropic suffered a significant code leak involving its Claude AI. The exposed code gave an unfiltered look at the internals of one of the most capable language models in production, from safety mechanisms to reasoning architecture.
The leak raises immediate questions about intellectual property protection in the AI industry. When the core code behind a major model becomes public, the security and competitive implications extend far beyond one company.
The pace of artificial intelligence development is often described as a technological arms race.

Introduction: The Great AI Security Wake-Up Call
Every week, a new model is released, a new capability is unveiled, and the industry seems to be sprinting toward an intelligence singularity. But beneath the hype, the revolutionary breakthroughs, and the billion-dollar valuations, lies a critical, often overlooked vulnerability: security.
In a stunning and deeply concerning development, Anthropic, the creator of the highly capable Claude LLM, has been implicated in a significant code leak. This isn't just a minor data breach; this is a potential exposure of core intellectual property—the very engine that powers one of the most advanced models in the industry.
For developers, investors, and AI enthusiasts alike, this incident serves as a brutal, high-stakes warning. It forces us to pause and ask: How secure is the foundation of the next generation of computing? In this deep dive, we will dissect the mechanics of this leak, analyze the profound implications for AI development, and outline the critical security measures that must be adopted immediately to prevent the next "tragic mistake."
The Anatomy of the Breach: How Did Claude’s Code Get Out?
A code leak of this magnitude suggests a failure point that is far more systemic than a simple phishing attack. When discussing the security of a foundational model like Claude, we are not just talking about leaked text; we are talking about the architecture, the training data pipelines, the proprietary fine-tuning methods, and the very weights that define the model’s intelligence.
The specifics of the leak are still emerging, but the general consensus points to a breach in the development or internal repository environment. This type of leak can originate from several vectors, each carrying catastrophic implications:
Insider Threats: The most dangerous vector. If a malicious actor or a disgruntled employee gains access to the internal codebases, they can exfiltrate massive amounts of proprietary information with minimal detection. Supply Chain Vulnerabilities: AI models rely on thousands of third-party libraries, APIs, and cloud services. A vulnerability in any single component can act as a backdoor into the core system. Misconfigured Cloud Storage: Often, the most common culprit. Developers accidentally leave highly sensitive repositories—containing model weights or API keys—publicly accessible or improperly secured within cloud environments.


